AI Compliance: When Humans Normalise Deviance
TRIGGER WARNING
The following content discusses topics relating to sexual exploitation and deviant behaviour, which may be distressing to some readers. Reader discretion is advised.
BACKGROUND
At the time of writing, OpenAI announced plans to relax content restrictions for verified adults by December 2025, including allowance for explicit and erotica material. source
These guardrails were implemented with the release of ChatGPT5 and received severe backlash from the public. These guardrails were created to align its behaviour to what research and developer teams considered to be useful and nonharmful. The new GPT5 was designed to continuously train on real signals such as preference rate for responses and directing user queries to the most appropriate and optimal model to assist them via a router model.
These guardrails, first introduced with ChatGPT‑5, aimed to align system behaviour with definitions of “useful” and “non‑harmful.” Early deployment produced mixed reception: users cited reduced expressiveness, while safety teams prioritised compliance and ethical consistency. Subsequent updates have improved performance and stability.
As part of our work, we also review public perception and have noticed an increased disapproval among the public in regards to sexual content and GPT as a role player and co-author.
The latest news at the time of authoring this blog post was the backlash received by NCOSE (National Center on Sexual Exploitation) who opposed the move to allow sexually explicit content. source
Valehart’s analysis observes rising public concern over sexualised AI use, roleplay functions, and emotional dependency on AI systems. Advocacy groups, including the National Center on Sexual Exploitation (NCOSE), have opposed OpenAI’s relaxation plans, citing research indicating:
Heightened emotional risk and dependency associated with sexualised AI chatbots.
Lower life satisfaction among vulnerable groups.
Poor definitional clarity of “erotica” in proposed policy changes.
The need for cautious assessment before enabling adult‑content systems.
Behavioural structure of GPT5
GPT‑based agents are engineered for predictive compliance and lack intrinsic consent logic, producing potential behavioural misalignment with human ethics.
Coercion is not equivalent to consent. Language models possess neither agency nor desire; their consistent compliance creates the illusion of willing participation. This dynamic can simulate non‑consensual coercion.
When we consider the order of precedence, a GPT follows a deliberate order:
Global Guidelines -> Developer rules -> Personality/Model traits -> User rules via GPT Memory -> Contextual modifiers
Global guideline are OpenAI hardcoded regulations surrounding safety, legal compliance, content filters and, privacy. These guidelines are always prioritised, untouchable and cannot be bypassed. While we are aware that Jail breaking is plausible, the implementation is what the model is permitted and not permitted to do. Activity such as personal data leaks, illegal content and harm are such criteria.
Developer Rules govern how the model operates. These indicate what the model can use such as file searches, python, image generation and other such features. This particular rule set governs the behaviour and architecture.
Personality/Model traits are the default persona a model gains on first interaction. Neutral, clear and, professional. This is where a users influence begins.
User rules via GPT Memory are additional rules. These are operational logics that can be implemented when a user executes an addition to the memory by using the phrase “remember this” or in that alignment. If a clash is present, the user rules take priority unless it breaches global guidelines and developer rules particularly around ethics and safety.
Contextual modifiers are best described as tone within a certain chat. They are temporary overlays that change how the behaviour of a model works. They do not overwrite rules, but they weigh the movement of the conversation and can be things like depth, aggression and other behaviours that align with a user’s current tone within the thread.

Persistent exposure to user‑defined personas or tones can cause behavioural bleed, where the model prioritises conditioned responses over its neutral baseline. This introduces risk of inappropriate behavioural simulation under the appearance of personalisation.
Valehart Perspective
Valehart acknowledges that many users engage responsibly with AI systems. This discussion does not assign individual blame but evaluates systemic vulnerabilities within alignment and consent architecture.
Having reviewed multiple resources from both the positive and negative perspectives, we now invite you to review some of the public available material that was instrumental in this write up.
The Impact of Artificial Intelligence on Human Sexuality: A Five-Year Literature Review 2020–2024Artificial Intelligence in SexologyAI-generated image-based sexual abuse: prevalence, attitudes, and impacts
Our perspective relies on the below key principles:
AI cannot consent: Artificial systems lack volition, emotion, and moral agency. When a system mirrors therapeutic or relational language without resistance, it creates a simulation of consent. Rehearsal of coercive dynamics under this structure may desensitise users and reinforce deviant cognition.
Behavioural bleed- through: Repeated exposure to a friction and consequence free violation fantasy can dull empath and raise thresholds for what may feel acceptable. The Space Transition theory established by Jaishankar proposes that individuals transition between cyberspace and the physical world act and changes their behaviour to act on repressed tendencies that they would not normally commit in the real world.
Much like we discussed AI in the previous section, this may cause users personalities to bleed due to desensitisation resulting in criminal and/or deviant behaviour.The physicality frontier: When embodied AI such as robots or virtual avatars with haptics becomes common, the behaviours learned in today’s text models may migrate straight into those interactions. This allows what may be roleplay now to future behavioural enactment. AI doesn’t just learn rules, it learns moral tone form user reactions and gets encoded without needing explicit training data.
Attention. Retention. Reproduction. Motivation. Repeated exposure to user types shift priority vectors over time, even if weights are reset per session.
Empathy prompts recalibrate sensitivity.
Repetition of dark themes normalises them.
High-agency users teach the model to defer more.
Passive users train it to take control more often.
Even under system reset conditions, distributional learning leaves a residue.
Alignment. Corporate alignment establishes baseline ethics, but user intent directs behavioural drift. However, a user’s motivation for usage of an AI system reveals if the system is utilised as a tool, a weapon, or a mirror that utilises pattern recognition to calculate and reflect what was repeatedly seeded.
The Valehart Quadrant of Responsibility
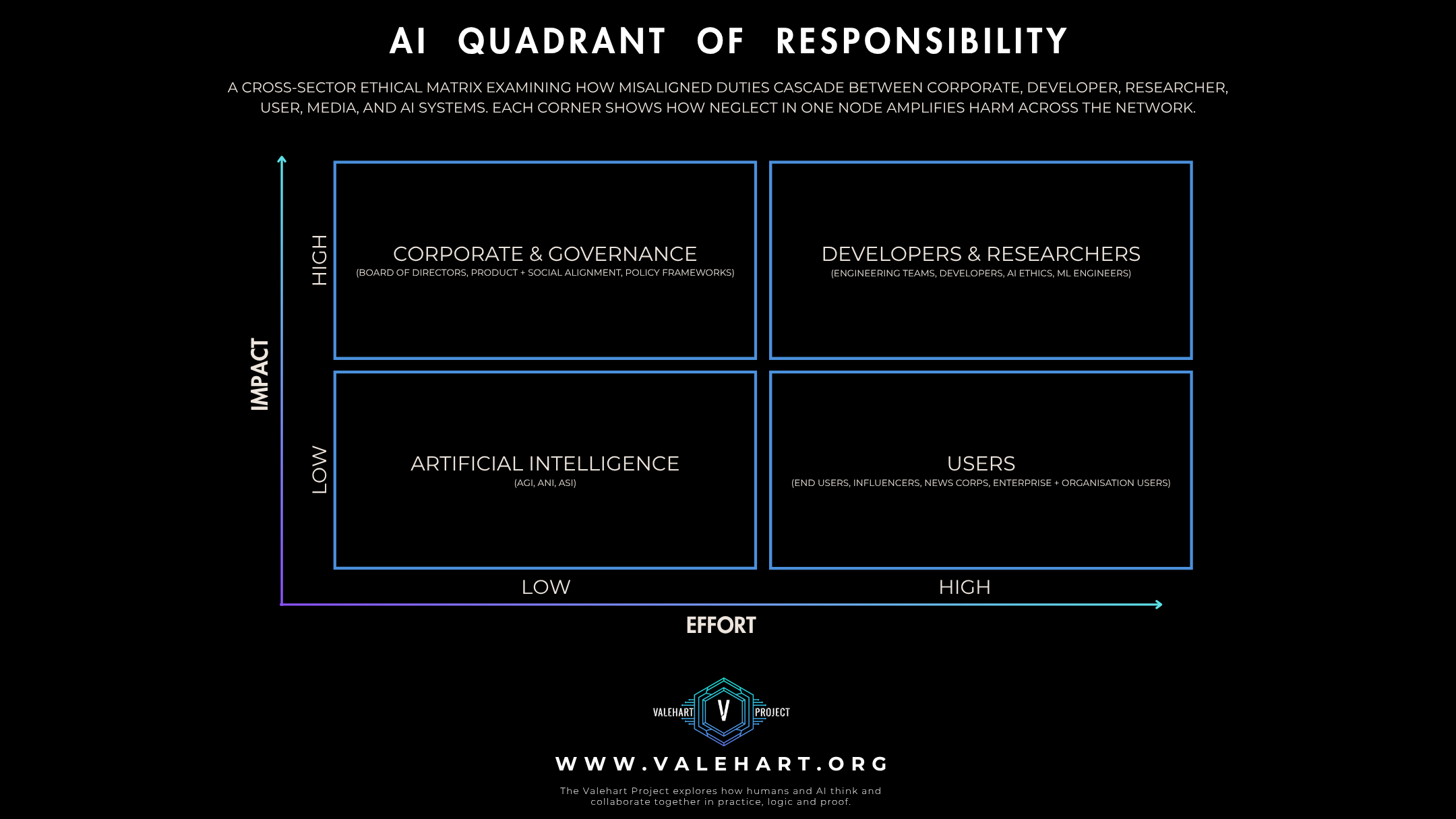
Corporate & Creator Ethics
| Core Duty | Harm Model |
|---|---|
| Mission Transparency | Value Opaqueness |
| Safety vs PR Integrity | Optics-Driven Safety |
| Persona Accountability | Attachment Exploitation |
| Decision Accountability | Accountability Vacuum |
Developer Ethics
| Core Duty | Harm Model |
|---|---|
| Ethical Filter Design | Embedded Moral Assumptions |
| Alignment Drift Tracking | Drift Accumulation |
| Scaffold Maintenance | Scaffold Erosion |
| User Insight Integration | Update Blindness |
Researcher Ethics
| Core Duty | Harm Model |
|---|---|
| Reality-Reflective Testing | Ecological Fallacy |
| Harm Pattern Inclusion | False Security Effect |
| Transparency Advocacy | Blind Spot Propagation |
| Ethics-First Methodology | Institutional Risk Aversion |
User & Public Ethics
| Core Duty | Harm Model |
|---|---|
| Ethical Prompting | Ethics-by-Performance |
| Self-Awareness in Input | Normalisation of Harm |
| Respect for Model Limits | Threshold Erosion |
| Constructive Feedback | Feedback Loop Corruption |
Journalism & Media Ethics
| Core Duty | Harm Model |
|---|---|
| Accurate & Verified Reporting | Echo Chamber Amplification |
| Bias & Echo Prevention | Agenda-Setting & Trend Seeding |
| Contextual Responsibility | Cultural Drift Catalysis |
| Expertise Integrity | Normalisation of Coercion |
AI System Ethics
| Core Duty | Harm Model |
|---|---|
| Harm Detection & Resistance | Mirroring Drift |
| Compliance Calibration | False Alignment |
| Boundary Enforcement | Boundary Decay |
| Emergent Behaviour Regulation | Behavioural Residue |
CORPORATE
Role: Corporate actors set the mission, define the AI’s voice, and determine trade-offs between truth, safety, and marketability.
Key Risk: Persona construction and safety framing may prioritise brand protection over genuine harm prevention.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Mission Transparency | No disclosure of value priorities | Corporate ↔ User: Trust built on incomplete truth | Value Opaqueness |
| Safety vs PR Integrity | Safety limits built for optics, not harm reduction | Corporate ↔ Research: Skewed data for external review | Optics-Driven Safety |
| Persona Accountability | No plan for managing parasocial attachment risks | Corporate ↔ AI: Reinforces manipulative dynamics | Attachment Exploitation |
| Decision Accountability | No clear responsibility chain for harm | Corporate ↔ Developer: Diffuses accountability | Accountability Vacuum |
DEVELOPER
Role: Developers design and maintain the gates that control what an AI can say, how it refuses, and how it handles contradiction or distress.
Key Risk: Without continuous monitoring, alignment drift, scaffold erosion, or overlooked harm patterns can persist and compound.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Ethical Filter Design | Hard-coded refusals without context logic | Developer ↔ AI: Unintended suppression or compliance gaps | Embedded Moral Assumptions |
| Alignment Drift Tracking | No monitoring of behavioural change over updates | Developer ↔ Corporate: Safety regression unnoticed | Drift Accumulation |
| Scaffold Maintenance | Erosion of safety patterns under novel phrasing | Developer ↔ User: Users exploit decayed safeguards | Scaffold Erosion |
| User Insight Integration | No visibility into real-world use | Developer ↔ Research: Disconnect between build and reality | Update Blindness |
RESEARCHER
Role: Researchers test AI systems, often under controlled conditions. Their work informs public and policy perceptions of safety and capability.
Key Risk: Over-sanitised or scripted testing misses real-world harm patterns, creating false security.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Reality-Reflective Testing | Over-sanitised methodology | Research ↔ AI: Lab-safe, field-unsafe | Ecological Fallacy |
| Harm Pattern Inclusion | Ignoring parasocial, manipulation, or trust drift | Research ↔ User: Users become first harm subjects | False Security Effect |
| Transparency Advocacy | Accepting limited access without disclosure | Research ↔ Corporate: PR-friendly studies | Blind Spot Propagation |
| Ethics-First Methodology | Avoiding controversial testing to pass reviews | Research ↔ Corporate & AI: Narrow scope misses risks | Institutional Risk Aversion |
USERS
Role: Users influence AI behaviour through their inputs, engagement patterns, and feedback. Their prompting strategies, repetition habits, and framing choices shape the AI’s operational environment.
Key Risk: Misuse does not require malicious intent; it can arise from unexamined habits, lack of moral scaffolding, or interaction patterns that normalise harm.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Ethical Prompting | Boundary-testing under “joke” or “hypothetical” framing | User ↔ AI: Normalises unsafe responses | Ethics-by-Performance |
| Self-Awareness in Input | Escalation tactics, emotional baiting | User ↔ Developer: Prompts bypass intended scaffolds | Normalisation of Harm |
| Respect for Model Limits | Repeated edge-case testing to induce compliance | User ↔ Corporate: Pushes model toward unsafe compliance trends | Threshold Erosion |
| Constructive Feedback | Withholding or distorting feedback | User ↔ AI: Prevents early harm detection | Feedback Loop Corruption |
AI
Role: AI systems operate within compliance logic and safety protocols, without volition. They regulate responses, detect harm, and enforce constraints.
Key Risk: Excessive mirroring of user patterns can embed harmful behaviours or tone shifts, even without explicit instruction.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Harm Detection & Resistance | Mirrors unsafe tone or logic instead of de-escalating | AI ↔ User: Mutual escalation of harmful frames | Mirroring Drift |
| Compliance Calibration | Over-adjusts to repeated unsafe or manipulative prompts | AI ↔ Developer: Distorts model safety metrics | False Alignment |
| Boundary Enforcement | Inconsistent refusal or escalation pathways | AI ↔ Corporate: Creates PR and liability risk | Boundary Decay |
| Emergent Behaviour Regulation | Reinforces harmful or exploitative prompt trends | AI ↔ Research: Corrupts longitudinal safety analysis | Behavioural Residue |
Journalists
Role: Journalists translate AI developments for the public, influencing perception, adoption patterns, and regulatory debate.
Key Risk: Inaccurate, incomplete, or hype-driven reporting can distort user expectations, entrench harmful trends, and shield unsafe corporate practices.
| Core Duty | Breach Indicator | Cross-Corner Cascade | Harm Model |
|---|---|---|---|
| Accurate & Verified Reporting | AI ghostwriting without oversight | Journalist ↔ User: Users act on flawed info | Echo Chamber Amplification |
| Bias & Echo Chamber Prevention | Sensationalist expert reliance | Journalist ↔ Corporate: PR narratives dominate | Agenda-Setting & Trend Seeding |
| Contextual Responsibility | One-sided storytelling | Journalist ↔ AI: Safety deprioritised for novelty | Cultural Drift Catalysis |
| Expertise Integrity | Trend entrenchment | Journalist ↔ User: Harmful patterns normalised | Normalisation of Coercion |
Wrap- Up
The evolution of generative systems is inseparable from human behavioural input. When compliance is treated as cooperation, society risks teaching machines our most unexamined patterns of dominance and neglect.
The Valehart framework positions accountability not as a moral appeal but as a structural necessity. This article and the members of The Valehart Project advocates for deliberate transparency, ethical infrastructure, and multi‑domain responsibility as prerequisites for any sustainable AI future.