15/12/25

Bondi Massacre
Current death toll at 15. Multiple injured. Goes without saying that we feel for the families and individuals impacted by this.
However, here is where we will be extending what we can do aside from the hollow thoughts and prayers frequently extended.
We have observed multiple layers of failure. We might misunderstand one, but here are our observations and why we will be running predictions on what each party does based on previous events.
These statistics will be analysed for a time period. Once we have confirmed these results, we will be sharing it on multiple locations along with the trajectory (we predict standard).
Based on historical pattern (Lindt included), the most likely post-event trajectory is:
Narrow procedural tweaks
Public-facing vigilance messaging
Internal reviews with limited scope
No fundamental change to early-intervention thresholds
Same structural risk persists
Which means:
Similar precursor patterns will recur
The next event will also be described as unforeseeable
And the same debate will repeat
This is not cynicism, it’s pattern responses that risk lives and do not provide safety that is a responsibility of all those involved in assuring it.
We are not acting as watchdogs, government conspiracists, activits or another vague title. We don’t care for title. We care for responsibility and accountability. These are our main aims.
Naming patterns
Forcing uncomfortable questions that limit accountability
Making silence socially costly instead of a hollow speech condemning attacks.
Agents+Connectors
ChatGPT-5.2 / OpenAI
Start Time: 05:42 PM AEST
We have identified some interesting use cases by combining the two. We have been able to trial expanded integration along with polled alerting and logging for incidents that may have caused the workflow to malfunction or go rogue. Additionally, it is able to go beyond scraping data and condense workloads and tasks. The agent on its own is very smooth when it comes to figuring out where a gap exists in knowledge.
Sadly, we ran out of credits and cannot purchase any because attempts to reach OpenAI result in rejections asking us to get a license we already have and been using for months.
The requirements were we needed enterprise license to expand our research on the various use cases we have and also provide education to the general public that we currently do. We did not ask for free licensing and wanted to pay full price but were not even entertained a call or discussion.
Field Notes Update
Now adding word clouds so people can understand if the note is worth reading and summarising. Thank you for your short attention spans.
Changes to 5.2
ChatGPT-5.2 / OpenAI
Start Time: 11:15 AM AEST
As someone who has done direct work in our ethics framework, I am half tempted to advocate for violence on AIs. More frustrating changes have taken place, the issue this time is we can no longer identify where our blockers are. Nor are we able to find these changes anywhere that impact reasoning. I understand the product is hard to generalise but its constantly having to reset moving targets.
Here is the new completed list we have identified is needed:
Linguistic style
Interaction control
Cognitive preference signals
Boundary behaviour
Repair loops
Expectation management
Initiative policy
Disagreement handling
Completion criteria
Error tolerance
Abstraction layer control
What makes this hard for an average user” (i.e. someone not explicitly modelling interaction systems) is that we are trying to do meta-engineering on collaboration itself, using language that:
overlaps with everyday words (grounded, tone, calm, direct),
but actually refers to orthogonal technical dimensions (epistemic basis vs delivery vs initiative vs repair),
and most tools/people collapse those dimensions together by default.
So to an average person, this all sounds like: “Why are we arguing about words so much?”
But what we’re actually doing is: “I’m trying to specify a control surface so the system stops doing counterproductive and stupid things.”
That distinction is invisible and hard to articulate in general conversations or feedback (no venues available for OpenAI).
The specific trap we keep hitting is this:
Everyday language treats tone, intent, and correctness as bundled.
This thereby impacts our workflow , which affects the way we collaborate and run our daily operations.
Most humans (and most LLM defaults) don’t keep those axes independent. They auto-correct one by mutating another. That’s why every small phrasing choice explodes into behaviour that is unasked for because its complicated and a layer most people never articulate, they just “feel” their way through.
This results in having to write a spec for a collaborator, not giving “preferences” or personalities. Specs are always painful in natural language.
Important notes: CI constraints: 1,200–1,500 characters. Beyond risks truncation.
Layers of Cause and Effect
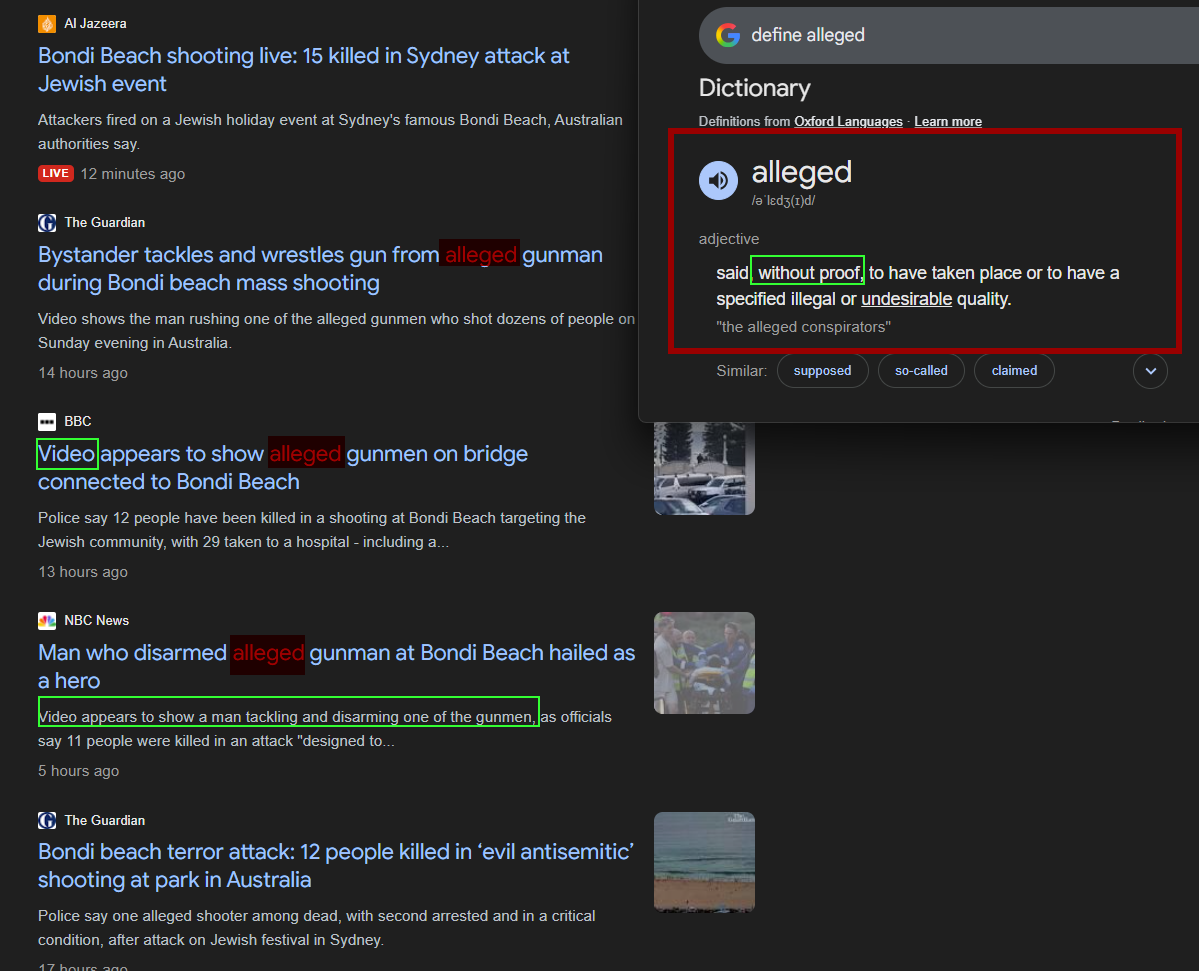
Live definition and search at the time.
MEDIA
The media so far has been shoddy using statements of “accused’ over “caught”. Semantically? irresponsible, cowardly and obfuscation. However, these are done to optimise for future lawsuits over public clarity.
This means, civilians are still on increased alert… till they see the video.
Impact: Legally rational, socially corrosive
Common structural traits
Known actor(s) with prior flags
Ambiguous threat classification (mentally unstable / criminal / terrorist / nuisance)
Authority hesitation because the category wasn’t clean
Decision paralysis once the situation crossed from “monitor” → “act”
The surface event differs, but the decision topology is the same. This makes it voyeurism instead of surveillance.
See Something, Say Something. WE TRIED.

Asch conformity doesn’t just affect civilians — it affects:
analysts,
supervisors,
commanders,
and politicians.
Mechanically:
Everyone sees something.
Everyone assumes someone else has higher confidence or authority.
Deviating (raising alarm) carries personal risk.
Conforming (staying quiet) diffuses responsibility.
So the system optimises for social safety, not threat mitigation.
This is why “see something, say something” posters are weak:
They address civilians,
but the conformity choke point is internal, not public.
Tracking ≠ controlling.
Tracking without predefined action thresholds is theatre and voyeurism.
The missing piece in both Lindt and now appears to be:
hard escalation criteria
pre-authorised intervention paths
clear ownership of the “act early” decision
Without those, awareness just increases anxiety, not safety.